Music Recommender System
Dossier Technique de Projet de Fin d'Études
1. Présentation Générale du Projet
1.1 Contexte Académique
Ce projet a été conçu et développé dans le cadre du module Techniques d'Intelligence Artificielle. Il vise à démontrer la maîtrise d'une chaîne de traitement de données complète ("Full Stack Data"), allant de l'ingestion de données brutes non structurées à leur valorisation au sein d'une interface utilisateur interactive.
1.2 Problématique : Le "Filter Bubble" Musical
Les algorithmes de recommandation dominants (Filtrage Collaboratif utilisé par Spotify, Netflix) reposent sur les corrélations d'écoute : "Les gens qui ont aimé X ont aimé Y". Bien qu'efficace, cette méthode présente des limites majeures :
- Cold Start (Démarrage à froid) : Un nouvel album sans historique d'écoute est invisible.
- Bulle de Filtre : L'utilisateur reste confiné dans sa zone de confort statistique.
- Manque de Sémantique : L'algorithme ne "comprend" pas pourquoi deux musiques se ressemblent (ambiance, texture, émotion).
La solution proposée : Un moteur de recommandation basé sur le contenu ("Content-Based Filtering") utilisant le Traitement Automatique du Langage Naturel (NLP). En analysant les critiques (chroniques) rédigées par des humains, le système capture la dimension émotionnelle et stylistique de la musique pour proposer des recommandations basées sur le sens.
2. Vision Utilisateur & Parcours Fonctionnel
L'application se positionne non pas comme un lecteur de musique, mais comme un outil d'exploration assistée par intelligence artificielle. Elle s'adresse aux auditeurs exigeants ("Diggers") cherchant à explorer des niches musicales spécifiques.
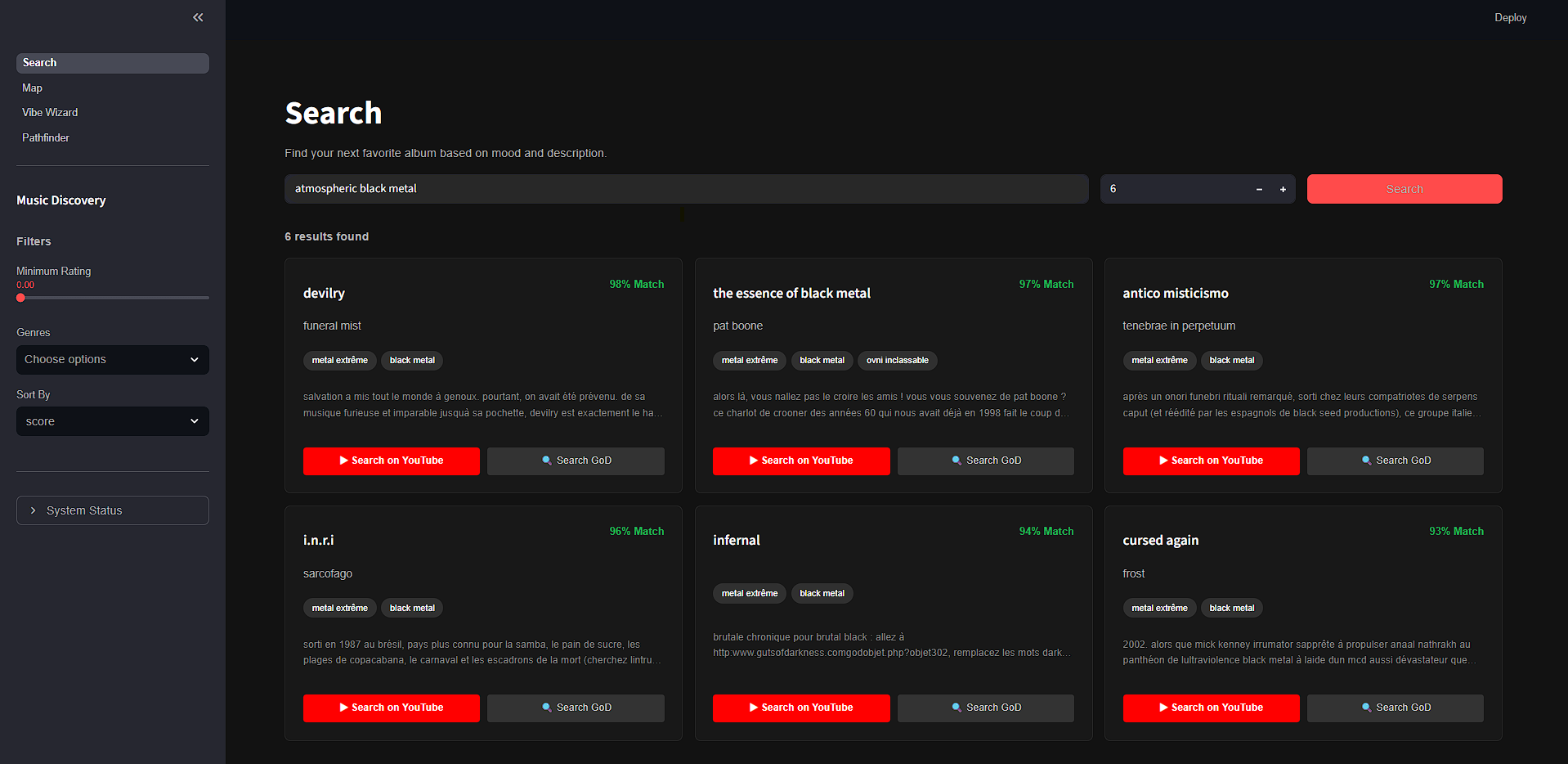
Parcours Utilisateur Principal
- Expression du Besoin : L'utilisateur exprime une envie, soit par mots-clés techniques (Mode Recherche), soit par description abstraite via le module "Vibe Wizard" (ex: "Une musique pour conduire la nuit sous la pluie").
- Traduction Intelligente : Le système utilise un LLM (Llama 3) pour interpréter cette intention et la convertir en vecteurs de recherche.
- Découverte Visuelle : Les résultats sont présentés sous forme de cartes enrichies, ou visualisés dans leur contexte global sur la Carte 3D.
- Écoute Exploratoire : Un clic sur un résultat déclenche instantanément la lecture d'un extrait (API Deezer) ou redirige vers une écoute complète (YouTube/Guts of Darkness), permettant une validation immédiate de la recommandation.
3. Architecture Générale
Pour garantir maintenabilité, scalabilité et robustesse, le projet respecte les principes de l'architecture Microservices (simplifiée pour le contexte académique). Chaque composant a une responsabilité unique et communique via des protocoles standardisés.
- Frontend (Streamlit) : Couche de présentation. Elle est "stateless" entre les sessions mais gère un "Session State" interne pour la navigation. Elle ne contient aucune logique métier lourde et se contente de consommer l'API.
- Backend (FastAPI) : Cerveau du système. Il expose des endpoints REST (`/search`, `/pathfinder`, `/explore`). Il gère la logique de RAG (Retrieval-Augmented Generation), la connexion à la base de données, et l'orchestration des appels aux services tiers (Groq, Deezer).
- Base de Données Vectorielle (Milvus) : Dockerisée. Elle stocke les embeddings (vecteurs de 384 dimensions) et effectue les calculs de similarité (Approximate Nearest Neighbor) à haute performance.
Flux de Données (Data Flow)
[Data Ingestion (Scraping)]
⬇
[Preprocessing & Cleaning]
⬇
[Vectorisation (Transformer)] ➔ [Parquet Metadata Storage]
⬇
[Milvus Indexing (HNSW)]4. Technologies et Outils
Chaque technologie a été sélectionnée pour répondre à une contrainte spécifique du projet.
| Technologie | Rôle | Justification du Choix |
|---|---|---|
| Python 3.10 | Langage Global | Standard de facto en Data Science/IA. Libraries matures (Pandas, Numpy, Pytorch). |
| FastAPI | Backend API | Performance asynchrone (ASGI). Génération automatique de la documentation (Swagger UI). Validation robuste des données via Pydantic. |
| Milvus 2.4 | Vector Database | SGBD spécialisé pour les vecteurs. Supporte l'indexation HNSW (Hierarchical Navigable Small World) pour des recherches en O(log N), indispensable pour le passage à l'échelle (> 1M items). |
| Sentence-Transformers | NLP Model | Utilisation du modèle pré-entraîné `all-MiniLM-L6-v2`. Compromis optimal entre vitesse d'inférence (adapté CPU) et qualité sémantique. |
| Groq (Llama 3) | Generative AI | Fournisseur d'inférence LLM ultra-rapide (LPUs). Permet une latence en temps réel (< 1s) critique pour l'expérience utilisateur (Vibe Wizard). |
| Streamlit | Frontend | Permet un prototypage rapide d'interfaces Data. Intégration native avec Plotly et Pandas. Idéal pour un POC (Proof of Concept) avancé. |
5. Modélisation des Données & Espace Vectoriel
Contrairement à une base de données relationnelle classique, le cœur du système repose sur la représentation vectorielle des données non structurées.
Construction de l'Embedding (Le "Sens")
Pour représenter mathématiquement un album, nous construisons un "Document" textuel synthétique concaténant plusieurs champs stratégiques :
Document = Titre + Artiste + Styles + Chronique ComplèteCe texte est passé dans le Transformer qui produit un vecteur dense de 384 dimensions ($d=384$). Chaque dimension capture une caractéristique sémantique abstraite (ex: dimension 42 = "agressivité", dimension 128 = "instrumentation électronique").
Schema de Données (Milvus Collection)
- Primary Key (int64) : ID unique de l'album.
- Embedding (float_vector[384]) : Vecteur de features. Indexé via HNSW (M=16, efConstruction=500).
- Métadonnées scalaires :
artist_name,album_name(stockées pour éviter un lookup couteux vers une DB SQL).
6. Fonctionnement Backend Détaillé
Endpoint Stratégique : POST /search
La logique de recherche implémente un pattern Hybride (Vector + Metadata) :
- Query Embedding : La requête utilisateur $q$ est vectorisée $\rightarrow V_q$.
- ANN Search (Approximate Nearest Neighbor) : Milvus scanne l'index pour trouver
les $N$ plus proches voisins de $V_q$ selon la distance Cosine.
Formule : $Sim(A, B) = \frac{A \cdot B}{||A|| ||B||}$ - Filtering (Post-Processing) : Les résultats bruts sont filtrés en mémoire
Python (FastAPI) pour appliquer les contraintes métier strictes (ex:
note > 4.0,style == 'Jazz').
Note : Le choix du post-filtering (vs pre-filtering dans Milvus) a été fait pour garantir une flexibilité maximale sur les critères complexes, au prix d'une légère surcharge CPU.
Intégration LLM (Le "Vibe Translator")
Le Vibe Wizard utilise une technique de Few-Shot Prompting. Nous envoyons au LLM un System Prompt strict lui demandant d'agir comme un expert musical et de traduire une description émotionnelle en une liste de tags techniques (genres, instruments, tempos) pondérés, qui sont ensuite injectés dans le moteur de recherche.
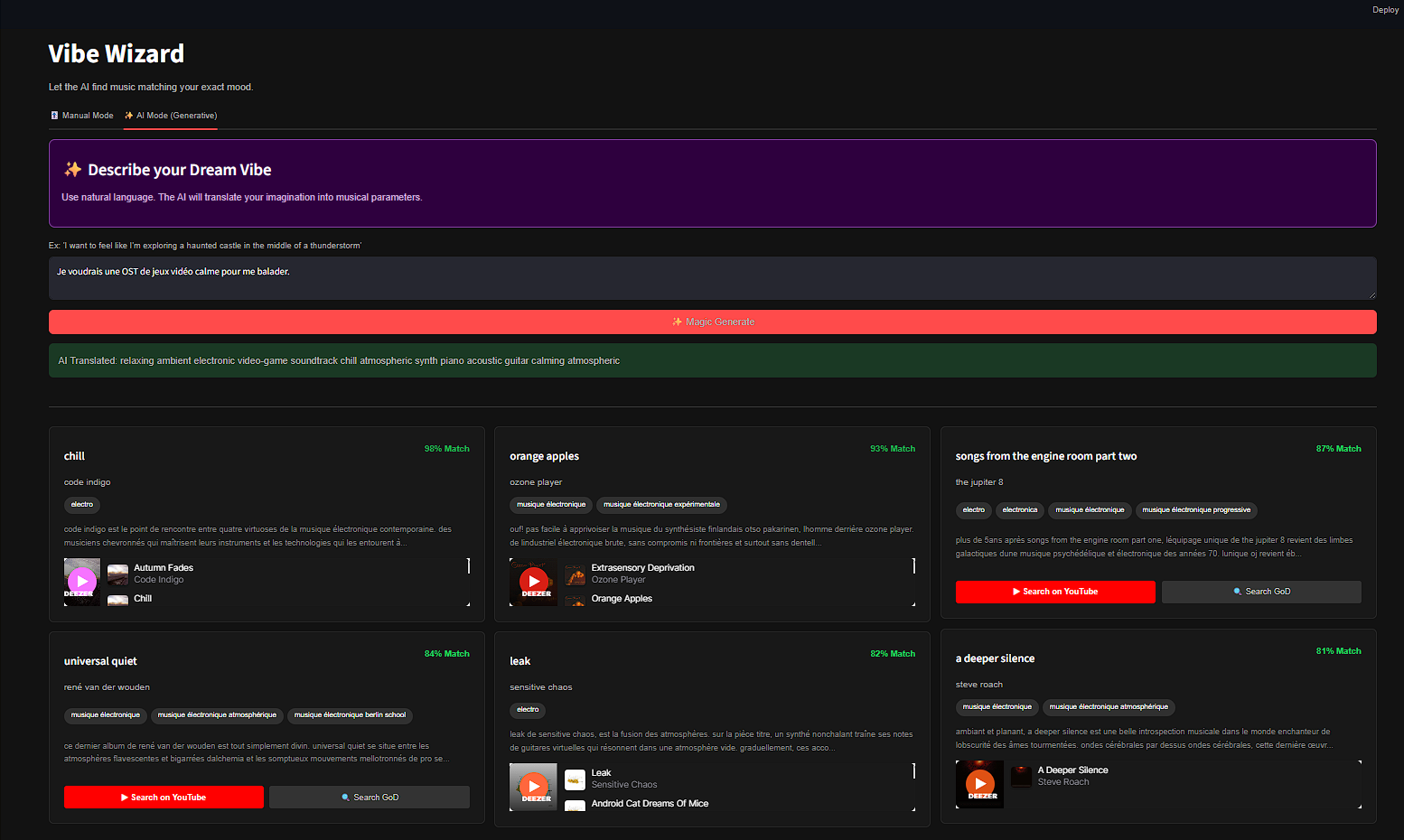
7. Implémentation Frontend & UX
L'interface a été conçue pour maximiser l'immersion "Dark Mode" (inspirée de Spotify).
Composant : Carte Album Intelligente
Chaque album est affiché via un composant réutilisable (`display_album_card`) qui gère dynamiquement :
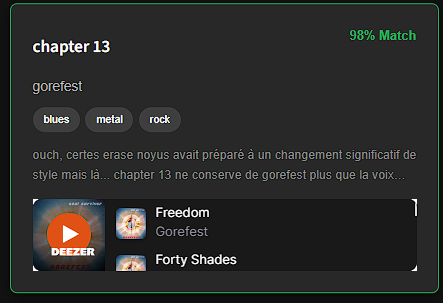
- Le Score Relatif : Plutôt qu'un score de similarité brut (ex: 0.65), nous affichons un pourcentage normalisé par rapport au meilleur résultat de la page. Le 1er résultat est forcé à 98% pour ancrer la perception utilisateur ("Spotify Trick").
- Le Lecteur Hybride : Le système tente d'abord de charger le Widget Deezer (via l'API publique Deezer). En cas d'échec (album absent), il génère dynamiquement un bouton de "Recherche Intelligente" vers YouTube, garantissant que l'utilisateur peut toujours écouter le résultat.
8. Visualisation de Données : La Map 3D
La page "Explore" constitue une prouesse technique de visualisation de données massives.
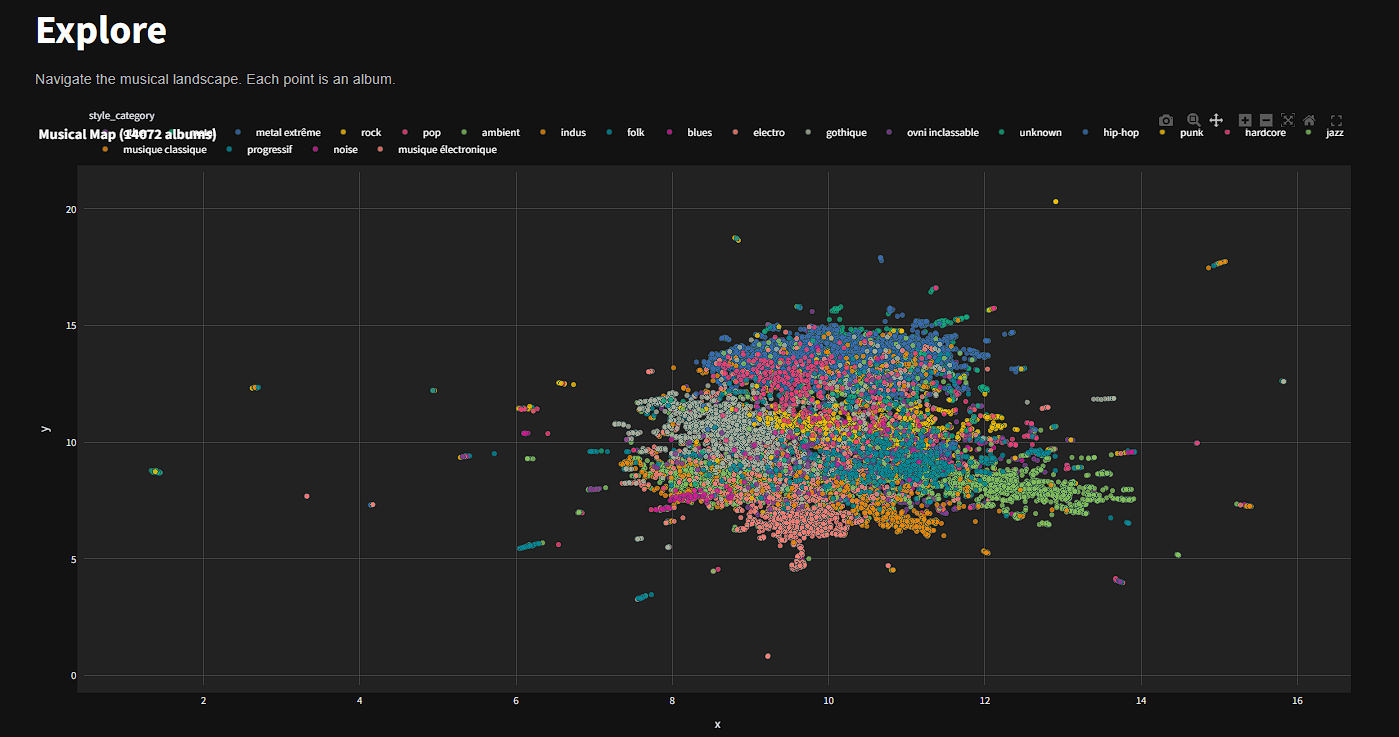
Principe Technique : Réduction de Dimensionnalité
Les vecteurs d'albums existent dans un espace à 384 dimensions, impossible à visualiser pour l'humain. Nous utilisons l'algorithme UMAP (Uniform Manifold Approximation and Projection) pour projeter ces vecteurs dans un espace Euclidien 3D (X, Y, Z).
- Préservation de la topologie locale : Contrairement à PCA, UMAP préserve les relations de voisinage. Deux points proches dans la 3D sont garantis d'être sémantiquement proches dans l'espace d'origine.
- Structure Globale : L'algorithme révèle la structure macroscopique de la musique. On observe physiquement des "continents" (Metal, Jazz, Electro) et des "isthmes" de transition (Jazz-Fusion, Industrial Metal).
Interactivité Avancée
La carte n'est pas statique. Elle implémente un callback bi-directionnel :
Clic sur un point ➔ Callback Streamlit ➔ Fetch API Deezer ➔ Affichage Sidebar.
Cela transforme la visualisation abstraite en outil d'exploration concret ("Digging").
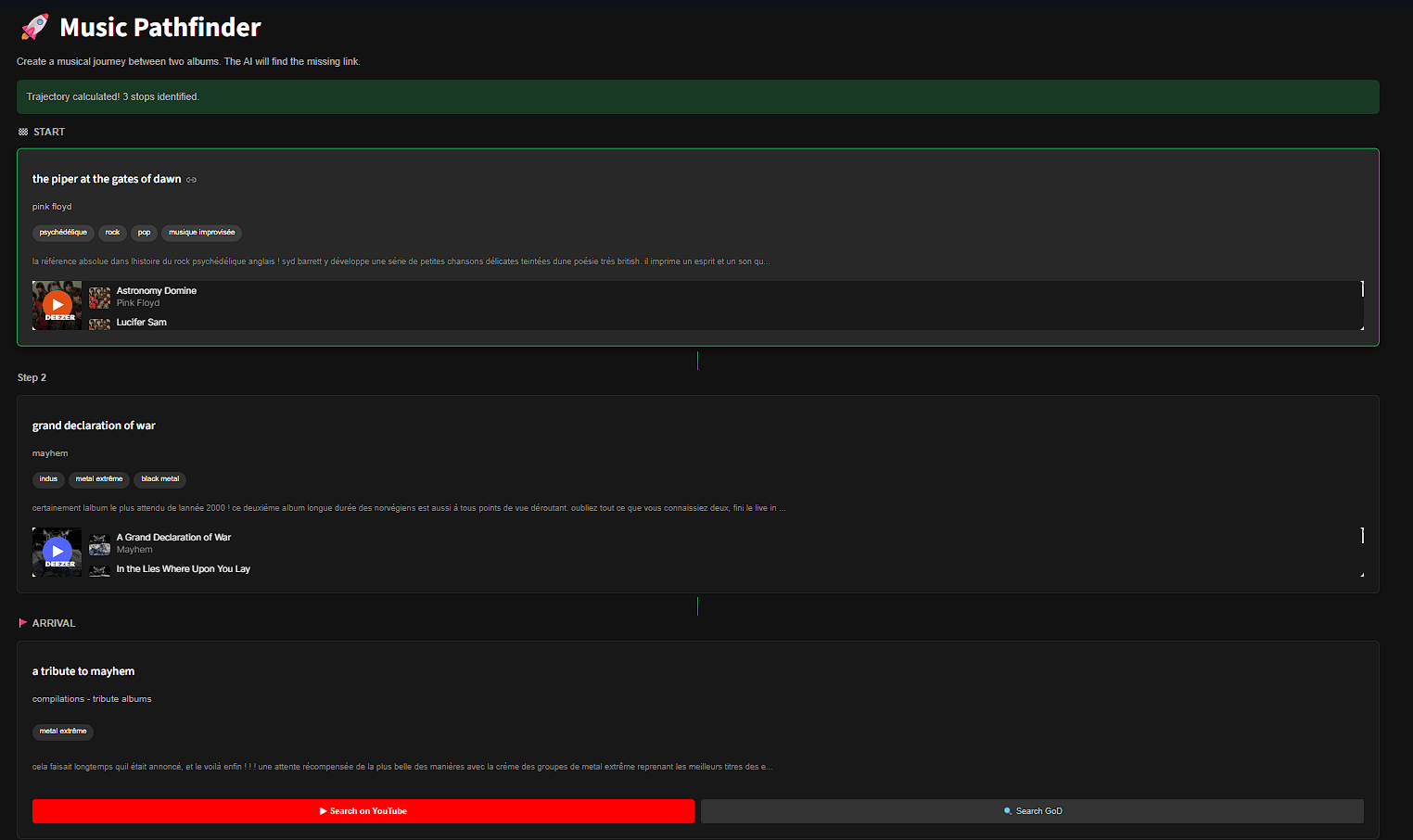
9. Cas Complexe : Le Music Pathfinder
Cette fonctionnalité innovante permet de tracer un itinéraire musical entre deux artistes arbitraires, générant une playlist de transition fluide.
Algorithme : Interpolation dans l'Espace Latent
Soit $A$ le vecteur de l'album de départ et $B$ le vecteur d'arrivée. Nous calculons une série de points $P_t$ le long du segment reliant $A$ à $B$.
Pour chaque point théorique $P_t$ (qui ne correspond à aucun album existant), nous effectuons une recherche Nearest Neighbor pour trouver l'album réel le plus proche dans notre base de données.
Défis & Solutions
- Problème de Répétition : Si deux points d'interpolation sont trop proches, ils "tombent" sur le même album voisin.
- Algorithme de Deduplication : Nous avons implémenté une heuristique "Look-ahead". Si le plus proche voisin est déjà dans le chemin, l'algorithme inspecte les voisins de rang $k+1, k+2...$ jusqu'à trouver un album inédit, garantissant un chemin varié.
10. Bilan & Perspectives
Ce projet a permis de développer une expertise concrète sur les architectures IA Modernes (RAG/Vector Search). Il répond à la problématique initiale en proposant une méthode d'exploration musicale libérée des biais de popularité.
Apports Techniques Majeurs
- Maîtrise de l'écosystème Vector Search (Milvus, Embeddings).
- Intégration de LLM en production pour des tâches de raisonnement (pas juste de génération de texte).
- Conception d'une UX fluide pour rendre accessibles des concepts de Data Science complexes (Espace latent, vecteurs).
Pistes d'Amélioration (Roadmap)
- Analyse Audio (Hybrid RAG) : Enrichir les vecteurs texte avec des features audio extraites directement des fichiers mp3 (MFCC, Spectrogrammes via Librosa) pour une précision accrue sur l'instrumentation.
- Feedback Loop : Utiliser les clics utilisateurs pour affiner le modèle d'embedding (Fine-tuning via Triplet Loss).
- Déploiement Cloud : Migration vers une architecture Serverless (AWS Lambda + Pinecone) pour réduire les coûts d'infrastructure.